Shortly, what is the Mistral AI’s Mistral 7B? It’s a small yet powerful LLM with 7.3 billion parameters. When tested, this model does better than both Llama 2 13B and Llama 1 34B. It also comes close to another model, CodeLlama 7B, when used for coding tasks but still does well with English tasks. It’s easily adaptable for different tasks. A version fine-tuned for chat surpasses Llama 2 13B chat.
So, when I first stumbled upon this model, I thought, “Why not give it a go on my MacBook M1 Pro with 16GB RAM?” Surprisingly, even with my basic setup, it worked super well. I reckon the fast performance is all thanks to this llama.cpp thing and the quantized .gguf format. If you’re curious, I’ve jotted down some easy steps below on how to get it running on your MacBook.
So, when I first stumbled upon this model, I thought, “Why not give it a go on my MacBook M1 Pro with 16GB RAM?” Surprisingly, even with my basic setup, it worked super well. I reckon the fast performance is all thanks to this llama.cpp thing and the quantized .gguf format. If you’re curious, I’ve jotted down some easy steps below on how to get it running on your MacBook.
Alright, so after upgrading to Ventura OS, my Xcode environment got a bit wonky. But don’t worry, I found a quick command that’ll patch it up. Check it out below!
sudo xcode-select --reset
xcode-select --installThe next step is hunting down the right version of the Mistral 7B model. I mean, I’m aiming for something close to the original 7B but still want to save some RAM. I found this quantized Q6_K version (for the completion) and this quantized Q6_K version for chat as it’s instruction-based. on TheBloke’s HuggingFace account. Word is, it’ll only eat up about 8GB of RAM when running, which sounds just right for my setup. Let’s grab that and put somewhere!
Once the model is downloaded, it’s time to get our hands dirty and run this thing using the command line. First things first, we gotta grab the llama.cpp repo and set it up with METAL support. Trust me, it’s easier than it sounds — like a walk in the park. Just follow these commands:
Once the model is downloaded, it’s time to get our hands dirty and run this thing using the command line. First things first, we gotta grab the llama.cpp repo and set it up with METAL support. Trust me, it’s easier than it sounds — like a walk in the park. Just follow these commands:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
mkdir build
cd build
cmake .. -DCMAKE_APPLE_SILICON_PROCESSOR=arm64
make -jCheck the ./build/bin/main — if it’s there, then everything is ready for the inference. Run it with the following command (do not forget to replace the path of the downloaded .gguf file):
./build/bin/main --color --model "/Volumes/GregSSD/LLM/mistral7b/mistral-7b-instruct-v0.1.Q6_K.gguf" -t 7 -b 24 -n -1 --temp 0 -ngl 1 -insAlright, moment of truth! Let’s see how this baby runs:
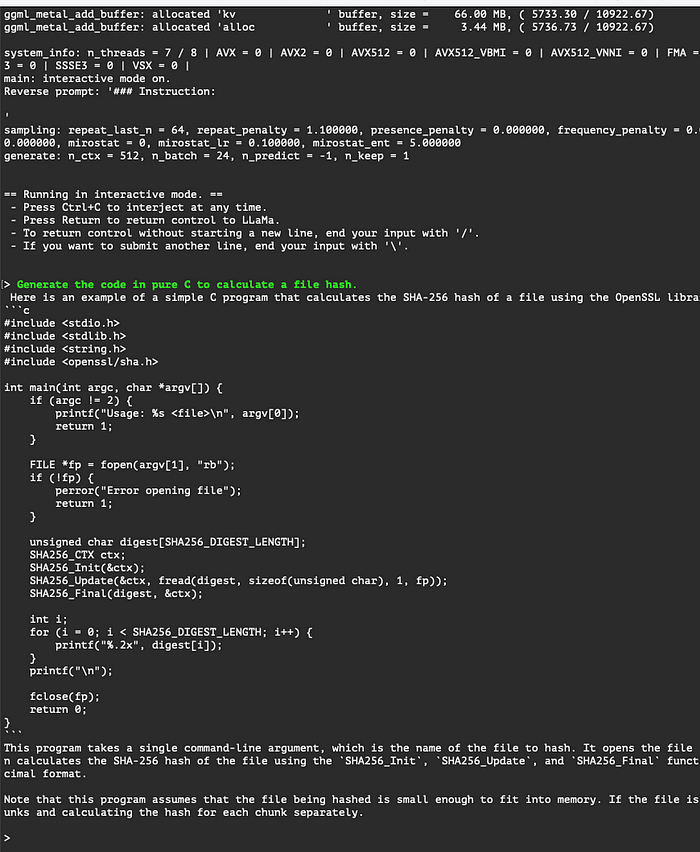
llama_print_timings: load time = 30830.61 ms
llama_print_timings: sample time = 705.00 ms / 474 runs ( 1.49 ms per token, 672.34 tokens per second)
llama_print_timings: prompt eval time = 11926.32 ms / 31 tokens ( 384.72 ms per token, 2.60 tokens per second)
llama_print_timings: eval time = 25413.28 ms / 475 runs ( 53.50 ms per token, 18.69 tokens per second)
llama_print_timings: total time = 190365.77 msIt takes llama.cpp few seconds to load the model but the inference speed is impressive. Now let’s play with it using llama-cpp-python library. First, let’s install (or upgrade) the library with METAL support.
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dirThen, do the rest of the magic:
from llama_cpp import Llama
model = "/Volumes/GregSSD/LLM/mistral7b/mistral-7b-instruct-v0.1.Q6_K.gguf" # instruction model
llm = Llama(model_path=model, n_ctx=8192, n_batch=512, n_threads=7, n_gpu_layers=2, verbose=True, seed=42)
system = """
Follow the instructions below to complete the task.
"""
user = """
Create a PHP script to scan a directory and print the contents of the directory.
"""
message = f"<s>[INST] {system} [/INST]</s>{user}"
output = llm(message, echo=True, stream=False, max_tokens=4096)
print(output['usage'])
output = output['choices'][0]['text'].replace(message, '')
print(output)And the result of the code execution:
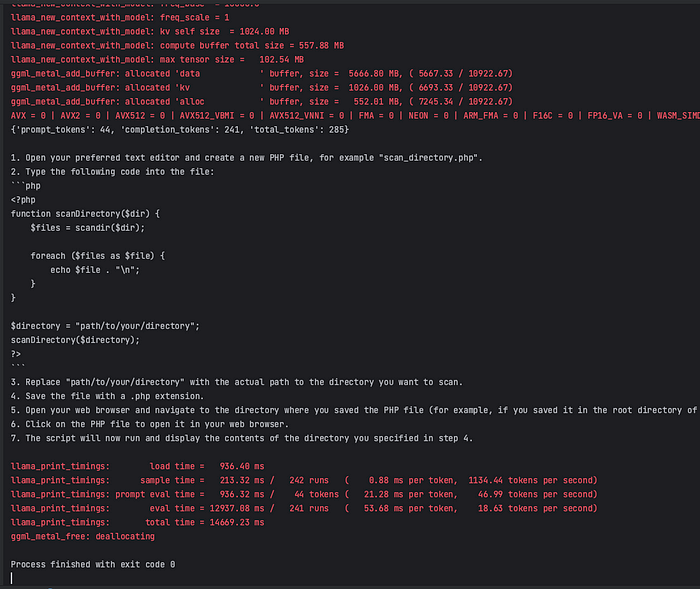
Whoa, 47 tokens a second? Not too bad. But I believe we can juice it up a bit more. Maybe mess with the batch size or fiddle with those llama.cpp settings. That’s my next mission. In the meantime, have a blast playing with this top-notch model on some pretty basic gear. Enjoy!